


For years, enterprises evaluated Generative AI through outdated lenses such as token cost, content accuracy, and prompt optimization. However, when it comes to test case generation, Generative AI operates on a fundamentally different level. It goes beyond simply producing outputs; it interprets contextual signals, intelligently expands test coverage, and uncovers hidden risk paths that traditional approaches often fail to detect.
Despite these capabilities, many teams still struggle to unlock its full potential, largely because they continue to measure success using legacy benchmarks.
In 2026, the real value of Generative AI in testing lies not in the sheer volume of test cases it generates, but in its ability to drive autonomy, enhance coverage intelligence, and integrate seamlessly into engineering workflows, enabling organizations to leverage it as a strategic quality engineering asset rather than just another automation tool.
Why Generative AI Test Case Generation Is Different in 2026
Most organizations initially approached test case generation as a content creation task. On the surface, that assumption feels logical. If AI can generate text; it should be able to generate test cases faster and at scale. And in the early stages, that’s exactly what teams experience: quicker outputs, more test scenarios, and a sense of immediate progress. But over time, this perspective begins to fall short. Because test case generation isn’t about producing content, it’s about making decisions. It involves understanding what needs to be tested, identifying where the highest risks lie, and anticipating how systems might fail in ways that aren’t immediately obvious.
This is where Generative AI starts to behave very differently from traditional approaches. It doesn’t just generate test cases line by line; it interprets inputs, connects multiple signals, and makes implicit decisions about the system. It determines which scenarios are meaningful, which ones can be deprioritized, and where potential vulnerabilities might exist. These decisions are not straight forward; they depend on context, including incomplete requirements, evolving user behavior, system dependencies, and domain-specific constraints. That’s what makes this shift so important. Traditional automation is rule-based and executes what is already defined.
Generative AI, however, operates in the space between what is defined and what is possible. It brings a level of contextual reasoning that goes beyond predefined logic. And once teams begin to recognize this, their approach starts to change. The value is no longer measured by how many test cases are generated, but by how effectively those tests reflect real risk and improve quality outcomes. This is where Generative AI moves from being a productivity tool to becoming a meaningful part of quality engineering decision-making.
The Role of Multi-Dimensional Signals:
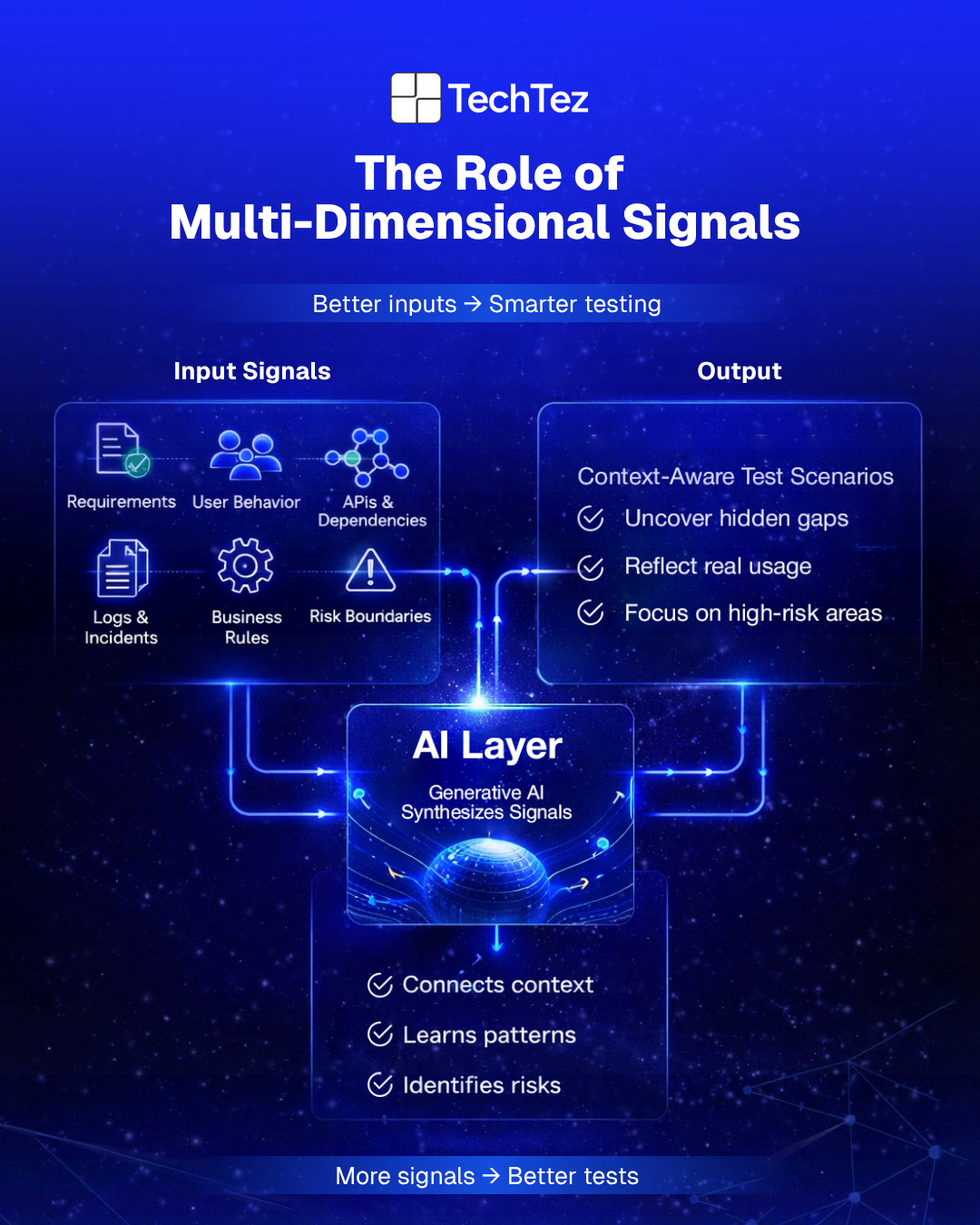
To generate test scenarios that actually matter, Generative AI needs proper context. And not just one type of input, but multiple layers of it.
In real-world systems, no single source tells the full story. Requirements might be incomplete or constantly evolving. User behavior rarely follows expected paths. Systems are connected through APIs and dependencies that aren’t always visible at first glance. Add to those logs, past defects, and historical incidents, and you start to see how complex the testing landscape really is.
Generative AI operates by bringing all of these signals together. It looks at requirements but also considers how users interact with the system in practice. It factors in system contracts and dependencies, while also learning from what has already gone wrong in the past. Domain constraints and business rules add another layer, helping it understand what truly matters from a functional and business perspective. Even risk boundaries for what failure would actually mean in a real-world scenario to become part of the equation.
Individually, these signals offer limited insight. But when combined, they create a much clearer picture of where potential issues might exist and that’s where the real value lies.
Because the strength of Generative AI is not in processing one input at a time, it’s in synthesizing all of them. This is what allows it to move beyond surface-level test generation and produce scenarios that are more aligned with how systems actually behave.
Instead of generating generic test cases, it begins to surface context-aware scenarios ones that reflect real usage, hidden dependencies, and potential points of failure.
And that’s what ultimately makes the difference between more tests and better testing.
The Real Value: Generating the Right Tests
Most teams already have enough tests on paper. The real challenge is finding the right ones. The tests that matter are usually not obvious checks. They are the ones that:
- Question what everyone assumed was safe
- Uncover gaps between features, integrations, and real usage
- Expose fragile edge cases before users do
- Reveal risks no one thought to document
That is where Generative AI starts to earn its place.
Used well, it helps teams look beyond routine validation and focus on what could actually break. Instead of spending all their time confirming expected behavior, teams can use AI to spot blind spots, identify unusual scenarios, and bring attention to risks that are easy to miss in day-to-day delivery.
In 2026, strong testing is about how well they understand the system, how quickly they can recognize risk, and how confidently they can act on it. Generative AI adds value when it helps connect scattered signals and turns them into sharper testing decisions.
That is the difference between doing more testing and doing better testing.
A Framework for Evaluating Generative AI Test Case Generation in 2026
One of the biggest challenges teams faces with Generative AI in testing is not adoption, it is evaluation. Most teams can see that it does something. It generates tests, suggests scenarios, and clearly speeds things up. But when it comes to answering a more practical and important question “Is this actually improving our quality?” The answers often become unclear.
That’s where the confusion begins.
Because without a clear way to measure impact, it’s easy to mistake activity for real progress. A higher number of test cases or faster execution can create an impression of improvement, even when the actual quality outcomes remain unchanged. Over time, this gap between perceived value and real impact becomes more noticeable, especially in production environments.
In 2026, more mature organizations are starting to approach this differently. Instead of relying on assumptions or surface-level metrics, they are moving toward structured evaluation models like ROI frameworks but adapted for Quality Engineering. The goal is not just to prove that Generative AI works, but to understand where it delivers meaningful value and where it does not.
This shift changes the conversation. It moves teams away from asking how much AI can generate and toward understanding how effectively it contributes to better testing outcomes. It encourages a more grounded view of one that focuses on measurable improvements in coverage, risk detection, and overall quality, rather than just speed or scale.
And that shift is essential. Because without a clear framework for evaluation, even the most advanced AI capabilities can end up being underutilized, misunderstood, or overestimated.
Coverage Intelligence: Are You Seeing What You Missed Before?
At its core, testing is about understanding what might be missing. Coverage Intelligence focuses on how effectively Generative AI helps uncover those gaps not by simply generating more scenarios, but by identifying paths that were never explicitly considered, such as edge cases, hidden dependencies, or complex interactions across APIs, UI layers, and backend systems. The real question is not how many test cases are created, but whether the AI is helping teams see risks that would have otherwise gone unnoticed.
Decision Support & Prioritization: Are You Testing What Actually Matters?
Not every test carries the same importance, and experienced teams understand this well. This is where Generative AI needs to go beyond generation and support decision-making. It should help highlight high-risk flows, connect testing efforts to business impact such as revenue-critical journeys or failure-sensitive operations, and reduce noise by filtering out redundant scenarios. More importantly, it needs to adapt as priorities shift, because in real-world systems, change is constant, and testing must evolve alongside it.
Engineering Integration Depth: Does It Fit into How You Work?
This is where many AI initiatives begin to lose momentum. You can generate impressive outputs, but if they sit outside your day-to-day workflows, they rarely translate into real impact. Integration is what bridges that gap turning potential into something measurable, especially within modern quality engineering practices.
The real question is whether AI connects seamlessly with your CI/CD pipelines, fits into the tools your teams already rely on, and evolves alongside your systems rather than remaining in a disconnected layer. Teams that see real value do not treat Generative AI as an add-on they make it part of how engineering actually gets done. Without this level of integration, even the most advanced capabilities remain underutilized.

Why the Hype Around Generative AI for Test Case Generation Still Exists
Most enterprises have already explored their potential in some form. Industry research, including Gartner’s analysis on AI-augmented software testing, reflects a clear pattern of widespread experimentation, early adoption, and growing curiosity about its long-term value. Across organizations, the journey often looks similar. Teams have tried AI-assisted test generation tools. They have run proofs of concept against requirements, APIs, or user flows. And in many cases, they have seen early gains faster test creation, increased volume, and broader initial coverage. On the surface, the impact feels immediate, which is easy to see why the hype persists
As systems grow more complex and deployment cycles accelerate, traditional approaches struggle to keep up, often creating bottlenecks in the delivery process. In comparison, Generative AI feels like a breakthrough. It can ingest user stories, API contracts, logs, and historical test data, and generate test cases in minutes. What once took hours or even days can now happen almost instantly. For many teams, that shift alone feels transformative, as it removes a significant portion of manual effort and opens the door to faster, more scalable testing.
Early Gains vs. Long-Term Reality
The early hype around Generative AI in testing was predictable. Give any engineering team a tool that can generate test cases in seconds, and the first reaction will be excitement. But that excitement can be misleading. Speed creates visible output. It does not automatically create meaningful quality. That is the mistake many teams make. They confuse test volume with test value.
The latest World Quality Report 2025 makes that gap hard to ignore. While Gen AI adoption in quality engineering is rising, only 15% of organizations have scaled it enterprise-wide. The same report points to the real blockers: 67% cite data privacy risks, 64% integration complexity, and 60% hallucination and reliability concerns. In other words, the challenge is no longer “Can AI generate tests?” It clearly can. The harder question is whether those tests hold up inside real delivery systems.
And that is where the conversation gets more honest.
In real projects, poorly directed AI-generated tests often create a false sense of progress. The suite gets bigger, dashboards look busy, and teams feel faster. But none of that matters if coverage is repetitive, critical risks stay under-tested, and release confidence does not improve. Even the reported productivity gains need context: organizations in the same report saw an average improvement of 19%, yet one-third reported minimal gains. That is not a failure of AI. It is a reminder that output without judgment does not travel very far.
What Generative AI Does Reliably Well in 2026
In 2026, the most effective use cases for Generative AI in test case generation have become clearer. Enterprises that apply it thoughtfully are seeing measurable improvements in coverage, regression efficiency, and API testing quality. One of its strongest capabilities lies in rapid coverage expansion. Generative AI is particularly effective at identifying missed scenarios, generating edge-case variations, and exploring data-driven combinations. In mature teams, this often translates into significantly broader functional coverage, helping uncover “forgotten paths” that are easy to overlook in manual testing. The result is faster gap discovery and greater confidence in release of readiness.
Another area where Generative AI delivers consistent value is regression testing. In systems with well-defined contracts, it can accelerate regression suite creation, generate baseline tests after system changes, and even assist in refactoring legacy test suites. However, this efficiency comes with a caveat human review remains essential. Without proper curation, teams can end up with noisy, redundant, or overly complex test sets. When guided effectively, though, Generative AI can significantly reduce manual effort and support faster, more reliable release cycles.
Generative AI also performs strongly in API and contract testing. When provided with structured inputs such as OpenAPI or Swagger specifications, GraphQL schemas, or service contracts, it can generate accurate and production-ready test scenarios with minimal supervision. This makes API testing one of the most reliable and high confidence use cases for AI in 2026.
Where the Reality Still Breaks Down
Despite these advancements, Generative AI does not eliminate the need for human judgment, and several limitations remain. One of the most critical gaps is its lack of inherent understanding of business priorities and risk. AI does not naturally recognize which user flows are revenue-critical, which failures could impact reputation, or which defects have compliance implications. Without human guidance, this often leads to large but unfocused test suites that fail to prioritize what truly matters.
Another challenge lies in input quality. Generative AI amplifies whatever it is given good or bad. When requirements are vague, outdated, or inconsistent, the output reflects those weaknesses. This can result in redundant tests, false positives, or scenarios that offer little real value. As a result, teams with poor requirement discipline often see limited benefits, regardless of how advanced the AI may be.
Finally, exploratory and intent-based testing remain deeply human-driven. These approaches rely on intuition, curiosity, and domain understanding qualities that AI cannot fully replicate. While Generative AI can assist by suggesting areas to explore, it cannot replace skilled testers who think creatively, anticipate unusual user behaviour, and push systems beyond expected boundaries.

The Core Misconception: Test Generation ≠ Test Strategy
A defining lesson in 2026 is that generating test cases is no longer a hard problem; deciding which tests truly matter. Gen AI can rapidly draft thousands of test cases, but volume alone does not translate into quality, confidence, or release readiness. While Generative AI excels at producing test scenarios, it cannot independently determine test priorities, define the appropriate automation scope, or set acceptable release risk thresholds. These decisions require an understanding of business impact, customer behavior, regulatory exposure, and system criticality context that exists outside code and requirements.
Without a clear test strategy, teams often find themselves dealing with bloated test suites that are expensive to maintain, slow down pipelines, and create a misleading sense of coverage. On the surface, it may look like more testing is happening, but in reality, much of it adds little value. In contrast, high-performing teams take a more deliberate approach. They use Generative AI as an acceleration layer something that enhances and scales human intent rather than replacing it. The role of the team becomes more focused: defining risk, setting quality goals, and establishing decision boundaries, while Generative AI operates within those guardrails to execute at scale.
In 2026, the most effective testing organizations found this balance. They do not rely on AI to make all decisions, nor do they limit it to basic automation. Instead, they treat it as a force multiplier for strategy-led testing one that supports faster execution without losing control over quality. This approach allows teams to move quickly while still maintaining reliability, accountability, and trust in their systems.
How Mature Teams Use Generative AI in Testing Without Losing Control
Mature teams use Generative AI in testing as an accelerator, not as a decision-maker.
They start by defining risk, validation scope, and quality goals. AI is then used to generate and expand test scenarios faster, but test priorities are still set by the team.
The workflow usually looks like this:
- Define risk areas and critical business flows
- Use AI to draft and expand relevant test scenarios
- Review outputs to remove redundancy and fix weak logic
- Prioritize tests based on business impact and system risk
- Integrate approved tests into CI/CD with version control and traceability
- Reassess test relevance as the system changes
Human review remains essential. Teams validate what AI produces, improve scenario quality, and filter out low-value or repetitive coverage.
High-performing teams also treat AI-generated tests as maintainable engineering assets. That means governance, ownership, traceability, and regular updates as requirements evolve.
The result is practical: faster test design, broader scenario discovery, and stronger coverage without losing control over quality or risk. Generative AI adds value when it operates inside disciplined testing practices, not outside them.
Final Thoughts
Generative AI for test case generation has moved well beyond the initial hype. By 2026, the teams seeing real success are not the ones trying to automate everything, but those that understand where automation adds value and where human judgment still matters. They are deliberate about what to automate, what to review, and what to question, maintaining a careful balance between AI-driven efficiency and human oversight to ensure quality does not get compromised.
As AI models continue to evolve, their capabilities will only expand. Generative AI will increasingly learn from production failures, generate test scenarios based on real runtime behavior, and adapt more quickly to system changes. This will make testing more responsive, dynamic, and closely aligned with how systems actually operate in the real world.
Yet even as these advancements continue, one principle remains unchanged. Test quality is ultimately a human responsibility. It is shaped by domain knowledge, informed by risk judgment, and upheld through accountability- areas where human insight plays a critical role. Generative AI can support and scale these efforts, but it cannot replace them. And in 2026 and beyond, that balance is what defines truly effective testing.